
{kind=link}
Connecting Kafka to a third-party or external application is a time-consuming operation that necessitates creating multiple lines of code to automate data transfer processes. To avoid these issues, you can utilise the Apache Camel Kafka connector, which connects the Kafka environment to your desired external application for message production and consumption.
In this article, we will learn about Kafka, Apache Camel Kafka Connector, how to configure Camel Kafka and when and when not to use it.
Table of Contents
Introduction
Apache Kafka- Apache Kafka is an Open-Source Distributed Event Streaming platform that was created in 2010 by LinkedIn and is used to create recommendation systems and event-driven applications. Kafka has three key components: Kafka Producers, Kafka Servers, and Kafka Consumers. Producers and consumers of Kafka can send and receive real-time messages through Kafka servers.
Apache Camel – Apache Camel is a free and open-source integration framework that makes building integration systems simple and easy. It also enables end-users to integrate several systems using the same API, which supports a variety of protocols and data types while also being expandable and allowing the addition of custom protocols.
What is Apache Camel Kafka Connector?
The Apache Camel Kafka connector is a well-known adapter component of the Apache Camel ecosystem, which is an Open-Source Application Integration platform. You may connect to 300 external sources or third-party programmes like SQL Server and PostgreSQL with Apache Camel Kafka Connector to establish connectivity between Kafka servers and the appropriate applications. Furthermore, the Camel Kafka Connector allows you to easily integrate any applications, protocols, or endpoints into the Kafka environment without the need for any extra automation or the creation of a large amount of code. This enables you to create a painless integration procedure between Kafka and external applications for producing and consuming real-time messages.
Configure the Camel Kafka Connector for Integration
One must use the appropriate Camel Kafka connector plugins since Apache Camel allows you to link Kafka with numerous external systems or applications for producing and consuming data. In the procedures, you’ll learn how to use the sink and source connectors to create a basic integration between a SQL database and Kafka.
You must meet specific requirements in order to utilise the connector to implement the integration between a database and Kafka locally, i.e. on your local system. On your local workstation, you should have an active Kafka Server, Zookeeper Instance, and Kafka Connect framework. In addition, before beginning the integration procedure, you must first create Kafka topics.
- You can launch the Kafka server and Zookeeper instances at first. To start a Kafka server, open a new command prompt and type the following command.
$KAFKA_HOME/bin/kafka-server-start.sh $KAFKA_HOME/config/server.properties
- To start the Zookeeper instance, open a new command prompt and type the following command.
$KAFKA_HOME/bin/zookeeper-server-start.sh $KAFKA_HOME/config/zookeeper.properties
- You successfully started the Kafka environment by running the given commands. You can now build a Kafka topic to store real-time communications and retrieve them later.
- To create a new Kafka topic, open a new command line and type the command below.
$KAFKA_HOME/bin/kafka-topics.sh –create –bootstrap-server localhost:9092 –replication-factor 1 –partitions 1 –topic mytopic
- You generated a new Kafka topic called mytopic with one division and replication factor using the command above.
- Following the completion of the prerequisites for performing the integration procedure, the Camel-Kafka connector must be downloaded and installed according to the external application. Assume you’re integrating Kafka with a PostgreSQL database, in which case you’ll need to download the Apache Camel framework’s SQL connector component.
- The needed connector can be downloaded in two ways. You can either get the relevant connector from Apache Camel’s official website or clone the Apache Camel’s Github repository to get access to the Camel Kafka connector. You can use the connector in any way, depending on the external application you’re about to link with the Kafka environment
- Visit the Apache Camel Kafka official website to manually download the connector.
- On the Apache Camel Kafka welcome screen, click the “Download” button. You’ll be taken to a new website where you may get various Camel-Kafka components to download.
- Scroll down to the “Apache Camel Kafka Connector” portion when you’re about to download the Camel Kafka connector. You can also use the search box to find the Camel component you’re looking for.
- Click “Connectors download list” under the “Apache Camel Kafka Connector” section.
- You will now be taken to a new page that contains all of the connections as well as their documentation.
- Find the proper Camel Kafka connector for integrating Kafka with PostgreSQL among the wide array of connector listings. The sink and source connectors for connecting the PostgreSQL database with Kafka can be found by scrolling through the connectors list.
- By pressing the download icons on the sink and source connectors, you may now download them both. The Camel Kafka connectors have now been successfully downloaded to the local system.
- Using CLI tools like command prompt or power shell to get the Camel-Kafka connector is another simple option.
- To extract the Camel-Kafka connector, first create a home directory. The file path to the home directory, according to the official documentation, is
“/home/oscerd/connectors/.”
- Navigate to the “connectors” folder using the command below before downloading the connector packages.
cd /home/oscerd/connectors/
- To download the Camel-Kafka connector from the Github repository, open a new command line and type the following command-
wget https://repo1.maven.org/maven2/org/apache/camel/kafkaconnector/camel-sql-kafka-connector/0.11.0/camel-sql-kafka-connector-0.11.0-package.tar.gz
- You successfully downloaded the Camel-Kafka connection components after running the command above.
- Run the following command to unzip or extract the Camel-Kafka connector package-
untar.gz camel-sql-kafka-connector-0.11.0-package.tar.gz
- You’ve successfully extracted the Camel Kafka sink and source connectors to the connectors folder after running the aforementioned command.
- To complete the integration between PostgreSQL and Kafka, you must first download the driver component.
- To begin, go to the newly formed Camel-Kafka SQL package folder and run the following command to get the appropriate driver-
cd /home/oscerd/connectors/camel-sql-kafka-connector/
- The next step is to download the PostgreSQL driver using the “wget” command-
Wget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.2.14/postgresql-42.2.14.jar
- The Kafka connect framework must then be configured to establish a connection between the external application and the Kafka environment.
- Open the default or home directory on your local workstation where Apache Kafka is installed. Go to the “config” folder and open it. Various Kafka component script files can be found. Right-click on the file “connect-standalone.properties” and search for it. Use your favourite editor to open the properties file.
- Locate the “plugin-path” parameter in the properties files.
- Configure the “plugin-path” parameter as shown below after going to it.
plugin.path=/home/oscerd/connectors
- When you alter the parameter, you can change the plugin path attribute to your desired place. In this scenario, you specified /home/oscerd/connectors as the path where the Camel Kafka source and sink connectors were previously downloaded.
You successfully downloaded and configured the Camel Kafka connector to establish integration with external apps by following the procedures outlined above. After creating the connection setup, you can use the Camel Kafka sink and source connectors to integrate the Kafka environment with the external applications.
When to use Camel and Kafka together?
To use Camel and Kafka together, two options are available:
- Kafka for event streaming and Camel for ETL
- Camel Connectors embedded into Kafka Connect
Lets understand these options in details
1. Kafka for event streaming and Camel for ETL
Camel and Kafka complement each other effectively. As a bridge between the two environments, Camel’s native Kafka component is the ideal native integration point:
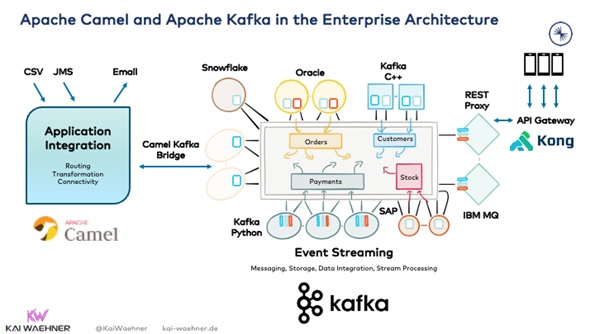
Camel and Kafka are shown living adjacent to each other in the architecture above. Camel is used for application integration in the business domain. Between the Camel integration application and several other applications, Kafka serves as the core nervous system.
Kafka’s advantage as a central integration layer is, its unique collection of traits inside a single infrastructure, which includes:
- At any size, real-time messaging is possible.
- True decoupling between multiple applications and communication paradigms is possible with storage.
- Backpressure handling is built-in, and events can be replayed.
- Stream processing and data integration
2. Camel Connectors embedded into Kafka Connect
Another option for combining Kafka and Camel is to use Apache Camel’s “Camel Kafka Connector” sub-project. Camel’s Kafka component (= connection) is not this feature! Instead, the deployment of camel components into the Kafka Connect architecture is a relatively new project.
The advantage: Can obtain hundreds of new connectors “for free” within the Kafka ecosystem this way.
However, evaluate the total cost of ownership as well as the entire work required to implement this strategy. One of the most difficult problems in computer science is application integration, especially when dealing with transactional data sets that require no loss of data, exactly-once semantics, and also no downtime. The more components you add to an end-to-end data flow, the more difficult it becomes to meet performance and reliability SLAs.
The disadvantage: combining two frameworks with different design philosophies and difficulties.
To run the integration natively with solely Kafka code, copy the business logic and API calls out of the Camel component and paste them into a Kafka Connect connector template. This solution provides for a cleaner architecture, end-to-end integration with an unified structure, and much easier testing, debugging, and monitoring.
When NOT to use Camel or Kafka at all?
The simplest method to begin evaluation is to eliminate tools that do not solve the problem.
The following scenarios are NOT supported by Camel or Kafka:
- Although native proxies (such as a REST or MQTT Proxy for Kafka) exist for particular use cases, a proxy for millions of clients (such as mobile apps) is available.
- An API management platform — nonetheless, these tools are typically used in tandem to create life cycle management or monetize APIs implemented using Camel or Kafka.
- A database for batch analytics workloads and complicated queries.
- An IoT platform with device management functionality – but direct native integration with (some) IoT protocols like MQTT or OPC-UA is viable and the way for (some) use cases.
- It’s a technique for hard real-time applications like safety-critical or deterministic systems, but it’s also applicable to any other IT architecture. Camel and Kafka are not the same as embedded systems
Conclusion
Kafka and Camel both are capable of integrating applications. They do, however, serve quite different purposes. Across business units, geographies, and hybrid clouds, Kafka is the central event-based nervous system. On the other hand If you need to integrate data within an application context or business unit, Camel is the technology to use.
To conclude, you may seamlessly integrate any apps, protocols, or endpoints into the Kafka environment with the Camel Kafka Connector without involving any external automated processes or creating a huge set of code.
Hevo Data, a No-code Data Pipeline, gives you a consistent and dependable solution for managing data transfer between a number of sources, such as Apache Kafka, and a range of Desired Destinations. Hevo Data allows you to export data from your selected data sources and load it using its strong integration with 100+ sources (including 40+ free sources).